Preprocessing vs EDA 전처리 vs 탐색적 데이터 분석 [빅공남! 통계같이 공부해요]

전처리(Preproecessing) vs 탐색적 데이터 분석(EDA) 빅데이터 분석기사 필기 2과목 공부에 앞서 두 개념에 대해서 이해하는 포스팅을 준비했습니다. 데이터 검정에서 빅데이터분석기사 목차에 대해서 확인할 수 있습니다. 2과목 빅데이터 탐색의 주제는 크게 3가지로 나뉩니다.
[빅데이터 분석기사 2과목 주제]
1) 전처리
2) 데이터탐색
3) 통계기법의 이해

3가지 굵직한 주제에서 알 수 있듯이 전처리, 데이터 탐색이라는 단어가 등장합니다. 갑자기 탐색? 이라는 단어가 왜 등장했는지? 전처리가 무엇인지? 에 관한 궁금증이 들 수 있습니다. 전처리(Preprocessing) 과 탐색적 데이터 분석(EDA) 비슷한 과정으로 혼용해서 쓰는 경우도 있는데 오늘 포스팅에서 두 가지가 어떤 과정인지 이해해보고자 합니다.

1. 데이터 분석에서 오래 걸리는 작업?
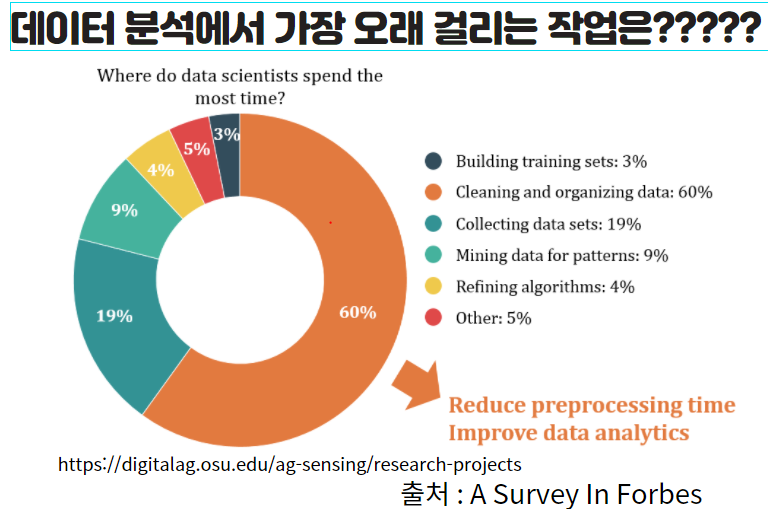
데이터 싸이언티스트가 가장 시간을 많이 쓰는 작업이 무엇인가?에 대한 서베이 결과가 있습니다. 아래 그림의 조사 결괄를 보면, 데이터 정제 및 가공 (60%), 데이터 수집(19%)로 확인이 됩니다. 데이터 수집 및 정제, 즉 전처리(Pre-processing) 80% 정도 응답으로 시간을 많이 쏟는다고 답변이 나왔습니다. 데이터 분석에서 데이터를 미리 처리 및 가공 (Preprecessoing)하는 작업에서 시간을 줄이는 것도 중요한 부분이라는 것을 알 수 있습니다.
2. 데이터 싸이언티스트의 업무 Flow
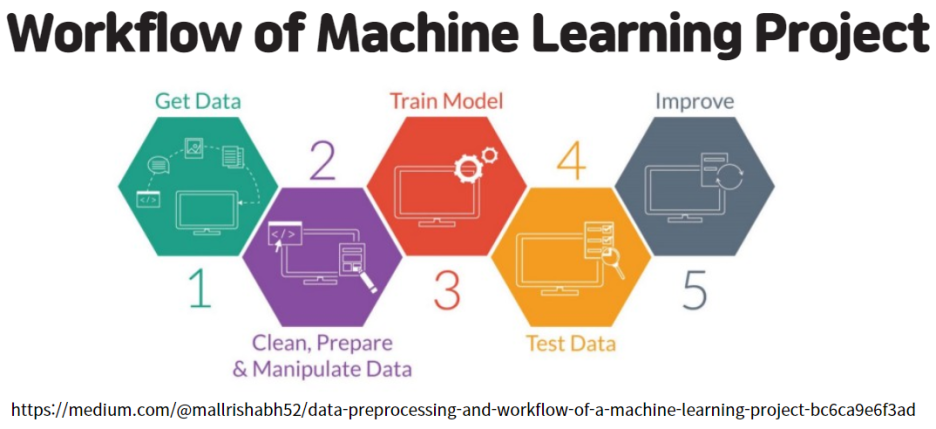
데이터 분석(EDA) 비슷한 과정으로 혼용해서 쓰는 경우도 있는데 오늘 포스팅에서 두 가지가 어떤 과정인지 이해해보고자 합니다. 먼저, 데이터 분석 업무 플로우는 아래의 그림을 보면 쉽게 이해할 수 있습니다.

위의 그림을 보면 데이터 싸이언티스트 업무 프로세스를 보기 쉽게 정리가 되어있습니다. 실제 세계(Reality)에서 수집된 데이터를 처리(Proecess)하고 정제(Clean) Data Set으로 EDA(Exploratory Data Analysis) 과정으로 넘어가는 것을 위의 그림으로 확인 할 수 있습니다.
다시 아래와 같이 또 다른 그림을 보면 전처리와 EDA 과정이 등장함을 알 수 있습니다. 두 과정은 동시에 또는 서로 왔다갔다 하면서 이루어지는 업무이기 때문에 혼용해서 개념을 사용하는 경우도 있습니다.
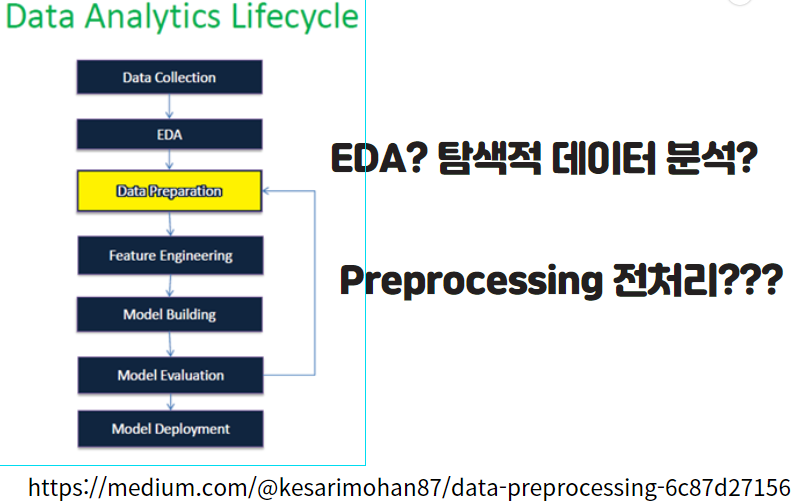
1) 데이터 수집 (Raw Data)
2) 데이터 전처리(Preprocessing)
☞ 정제된 Data Set 확보(Clean Data Set)
3) 탐색적 데이터 분석 (EDA)
Explorataroy Data Analysis
☞ 데이터 분석(Modeling)에 사용시 원하는 결과를
도출할 수 있는 Clean Data Set인지 파악
☞ 데이터 Set이 데이터 분석(Modeling)에 사용에
(★)부적합하면 다시 전처리(Preprocessing) 반복
4) 데이터 모델링(Modeling) & 알고리즘(Algorithm)
☞ 머신러닝(Machine Learning), AI 등..
5) 데이터 결론 도출, 검증, 시각화
☞ 의사결정, 보고서(Report)
6) 데이터 상품 출시
☞ 실제 생활(Reality) 적용
3. EDA vs 전처리 ??
1) 탐색적 데이터 분석(EDA)
데이터 모델링에 들어가기 전에, 수집된 데이터의 분포, 관계를 파악하는 과정(히스토그램, 산포도, 기초통계량 등으로 분포 파악)하고 모델링, 알고리즘에 사용될 수 있는 Data Set인지 파악함), 모델링 Iput에 사용하기 부족하다면 다시 정제(Cleaning).


2) 데이터 전처리(Preprocessing)
수집된 데이터에는 이상한(?), 극단적인(?), 공란의(?), 잡음(?)의 데이터가 섞여 있을 수 있음. 데이터의 가공 없이 데이터 분석 및 모델링을 하면 결과가 이상하게 나올 수 있음. 데이터를 분석에 사용할 수 있도록 정제(Cleansing)하고 가공하고 변환(Transformation)등을 거쳐서 모델링에 필요한 변수로 만드는 과정.


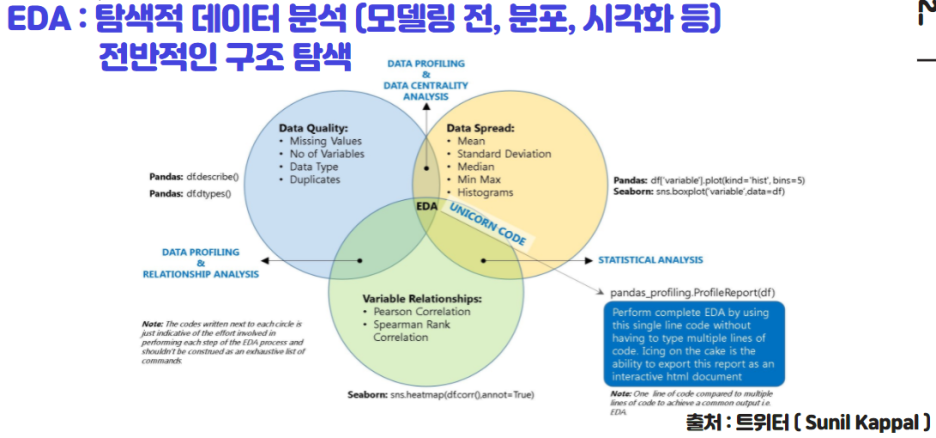
EDA(탐색적 데이터 분석)을 위의 그림을 보면 좀더 직관적으로 이해할 수 있습니다. 데이터 모델링 전에 데이터가 모델링에 적합한지 알기 위해서 데이터 전반적으로 구조를 탐색하는 과정입니다. 데이터 분포에 대해서 파악하고 결측치, 이상치 등등 데이터에 이상이 없는지 그리고 데이터 변수간에 상관성은 얼마나 있는지 통계적 방법으로 미리 탐색적 분석을 할 수 있습니다. 때문에 먼저 기술통계 영역에 대해서 지난 포스티까지 정리를 해왔었습니다. 위의 그림에서의 EDA를 대략 정리해보면,
1) Data Spread (기술통계 영역)
- Mean, Median, Mode
- Standard Deviation Variance
-
2) Data Quality (데이터 품질)
- Missing Value
- Outlier
- Data Type
- Duplication
3)Variable Relations (변수 상관성)
- Pearson Correlation
- Spearman Rank Correlation
5. EDA 파이썬???
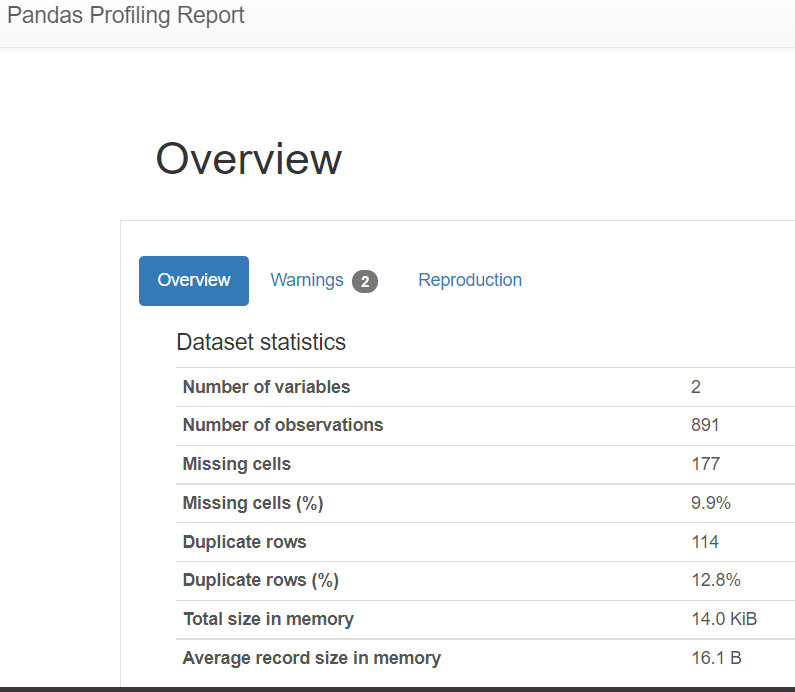
위의 그림에서 보면 EDA는 파이썬 판다스 라이브러리중에서 pandas_profiling_Profilereport를 통해서 해볼수 있습니다. 판다스 프로팡일링 라이브러리로 보고서를 불러오면 다음과 같이 Variable, Missing Cells(결측) Duplication Row(복제) 등등 을 한눈에 보기 쉽게 정리해서 보고서로 볼 수있습니다.
또한 아래 그림과 같이 변수간의 Correlation등을 시각화해서 한눈에 보기 쉽게 얼마나 관련성이 있는지 볼 수 있습니다.
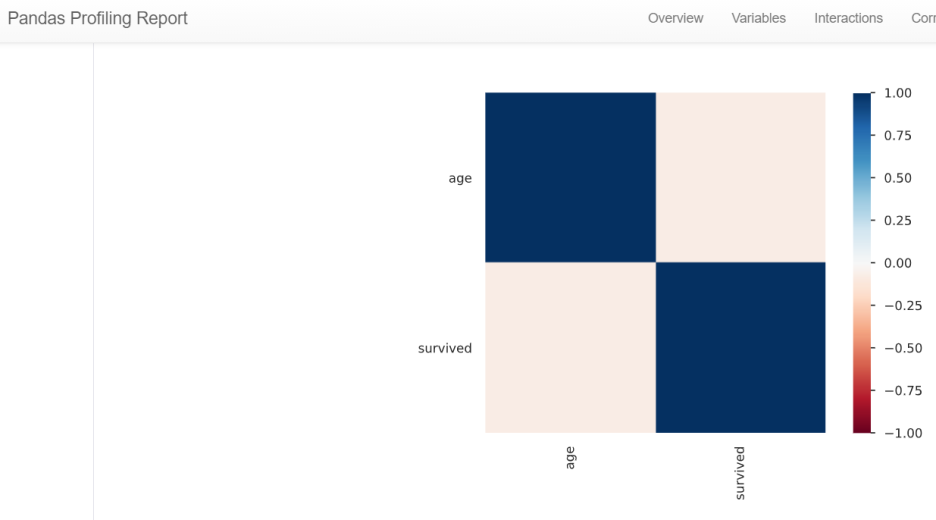
그래서 파이썬에서도 데이터 분석에 들어가기 앞서, EDA 과정을 통해서 변수를 사용해도 모델링 결과에 큰 문제가 없는지, 결측값, 이상값 들이 많이 있지는 않은지 중복데이터는 얼마나 존재하는지 등등을 미리 파악하고 다시 한번 데이터의 정제, 가공이 필요한지 확인 할 수 있습니다.
6. 데이터 전처리?
데이터 전처리에서는 특히 데이터 정제(Cleansing)에 관한 부분이 중요한 부분입니다. 이상치, 결측치 등이 있다면 적절히 데이터를 정제해서 모델링에 사용될 수 있도록 가공하기도 합니다. 그렇기 때문에 빅데이터 분석기사 2과목 데이터 전처리의 소주제로 이상값 처리, 결측값 처리, 변수변환, 과적합 등등이 있습니다.

[빅공남 유트브 채널 바로가기]

[빅공남! 통계 같이해요 바로가기]

[빅공남! 문과생을 위한 고등수학 13강]

[빅공남 전처리 vs EDA 영상링크]
'빅데이터 > 통계노트' 카테고리의 다른 글
| 결측값 결측치 종류 및 대체 (MCAR MAR MNAR) [빅공남! 통계 같이 공부해요] (0) | 2021.12.28 |
|---|---|
| 결측값 vs 이상값 Missing Value vs Outlier 이상치 vs 결측치 [빅공남! 통계같이 공부해요] (0) | 2021.12.28 |
| 통계 Box Plot Stem-Leaf 시각적 데이터 탐색 차트 [빅공남! 통계 같이 공부해요] (0) | 2021.12.28 |
| 왜도 Skew 첨도 Kurtosis (분포의 모양 기초통계량) [빅공남! 통계같이 공부해요] (0) | 2021.12.28 |
| 퍼짐정도 분산 표준편차 사분위편차(IQR) 변동계수 산포도 기초통계량(Degree of Dispersion) [빅공남! 통계같이 공부해요] (0) | 2021.12.28 |




댓글