이상값 이상치 Outlier 탐지 [빅공남! 통계 같이 공부해요]

빅데이터 분석기사 빅분기 이상값 이상치 Outlier 아웃라이어 탐지는 데이터 분석에서 중요한 이슈 중에 하나입니다. 데이터 검정 사이트에서 2과목 빅데이터 탐색의 주제를 살펴보면 이상값 처리라라는 주제가 있는 것을 확인 할 수 있습니다.
그래서 오늘 포스팅에서는 이상값, 이상치(Outlier)를 탐색을 왜 해야하는가?에 대해서 정리를 해보고 내용을 정리해보도록 하겠습니다. 오늘 공부에 도움되는 유튜브 영상 링크는 맨 아래 첨부하겠습니다.

1. 이상치(Outlier) 탐색해야 하는 이유?
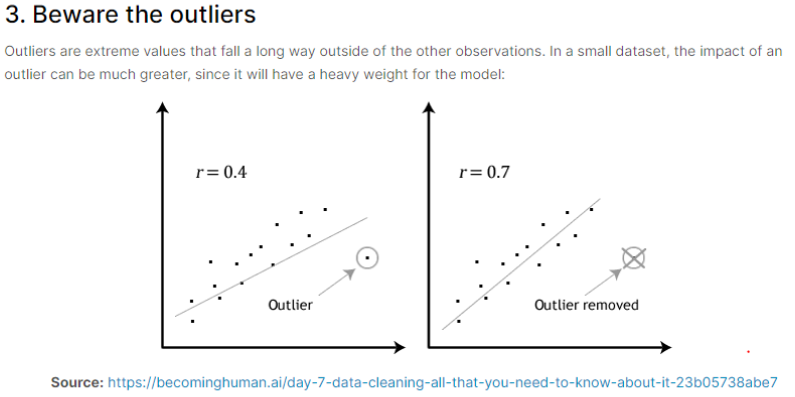
데이터들의 분포를 통해서 추세선을 찾아 내는 방법을 회귀분석(Linear Regression)이라고 합니다. 그림의 왼쪽 처럼 직선으로 우상향하는 추세가 있는데 이상치(Outlier)가 있다면 추세선은 좀더 아래로 내려오게 됩니다. 그래서 추세에서 멀어지게 됩니다. 그런데 만약 이상치(Outlier)가 없다면 추세선은 다른 점들의 추세와 비슷하게 맞출 수 있습니다. 회귀 분석으로 추세선을 찾는다는 것은 선을 통해서 결과를 예측할 수 있는 것을 의미합니다. Outlier를 적절한 범위에 놓는다면, 전체적인 Data의 추세(Trend)를 맞추고 비슷하게 예측을 할 수 있게 됩니다.
2. 이상치(Outlier) 탐색 방법 분류
이상치 탐지 방법은 여러가지 방법이 있지만 크게 3가지방법으로 나누어서 보려고 합니다.
1) 통계적 기법(기초통계량 활용)
평균(중심)에서 얼마나 떨어진 값들을 이상치(Outlier)라고 할 것인가???
2) 시각화(Visualization)
차트를 활용해서 시각적으로 이상치를 발견할 수 있을 것인가??
3) 머신러닝, 알고리즘, 모델링 등 분석기법 활용
3. 통계(기초통계량)값으로 이상치 탐지
지난 포스팅들을 살펴보면 기초통계량에 대해서 정리한 글들을 볼 수 있습니다. 기초통계량 중에서 중심경향성을 나타내는 기초통계량 값들과 산포도 기초통계량을 공부했습니다. 중심을 나타내는 값인 Mean, Mode, Median 값들과 흩어진 정도를 나타내는 표준편차, 사분위 편차를 활용해서 중심에서 어느 정도까지 정상 범위로 생각하고 그 밖의 값들은 이상치(Outlier)로 판단하게 됩니다. 변수가 1개일 경우 아래와 같이 평균, 표준편차, IQR의 범위를 이상치의 경계로 택할 수 있습니다.
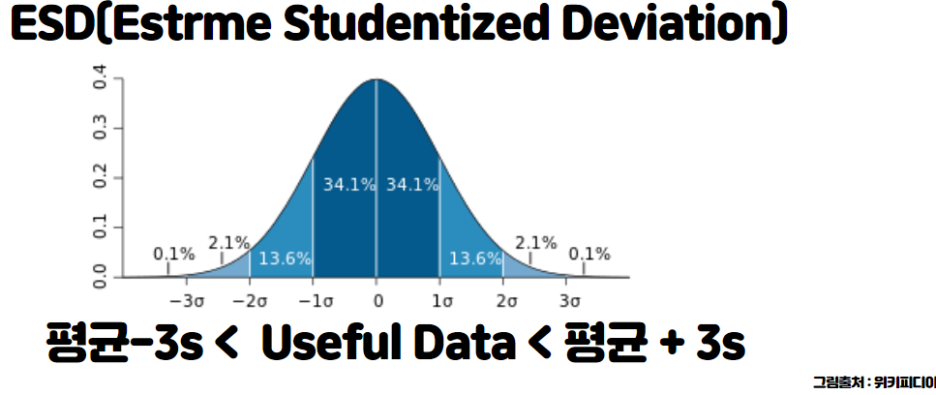
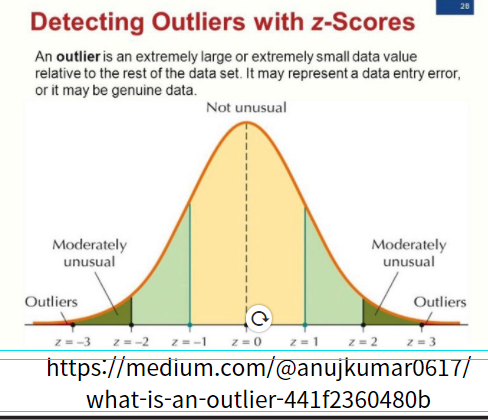
1) ESD(Estreme, Studentized Deviation)
☞ 평균에서 좌우로 3씨그마(표준편차)
2) 기하평균 활용
☞ 기하평균에서 좌우로 2.5씨그마(표준편차)
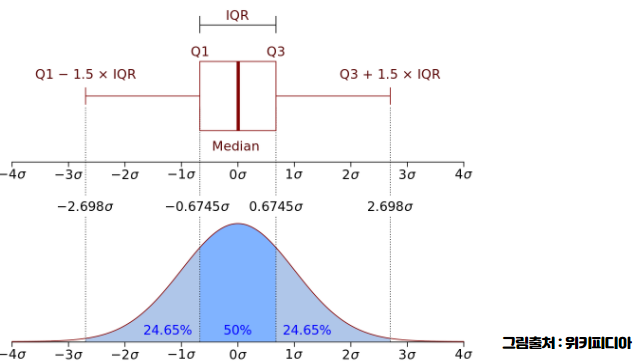
3) 사분위 편차 (IQR 활용)
☞ 2분위수(Q2, 25%)지점 + 1.5 x IQR
☞ 3분위수(Q3, 75%)지점 + 1.5 x IQR
☞ IQR = Q3(75%) - Q2(25%)
4. 시각화를 통한 이상치 탐지
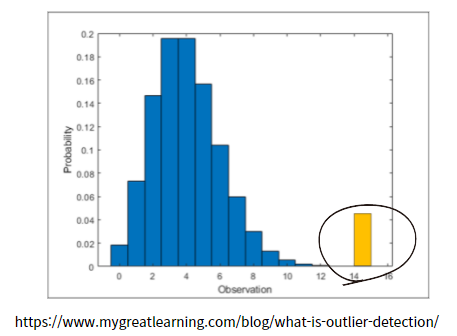
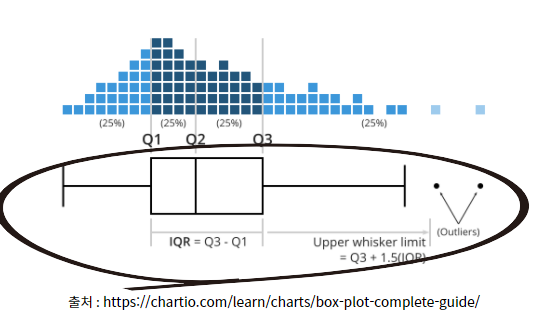
데이터를 차트로 시각화 해서 추세에서 멀어진 값들을 볼 수 있습니다. 히스토그램, 확률밀도 함수에서의 양쪽 끝 값들, Box Plot의 상한,하한( +, - 1.5 IQR)으로 눈으로 이상치 탐지 가능.
1) 히스토그램
2) 확률밀도함수
3) Box Plot
5. 머신러닝, 알고리즘 등으로 이상치 탐지
1) K-군집
K-군집은 비지도학습의 한 알고리즘 분석 방법인데 아래 그림 처럼 K-Menas 알고리즘을 떠올릴 수 있씁니다. 왼쪽 Data에서 k개의 중심에 해당하는 평균을 잡고 거기서 반경을 잡아가면 k개의 군집을 만들어 낼 수 있습니다.
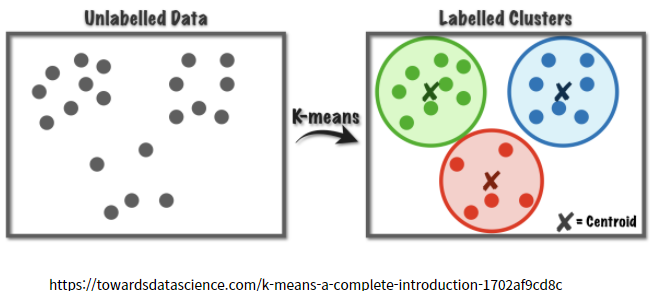
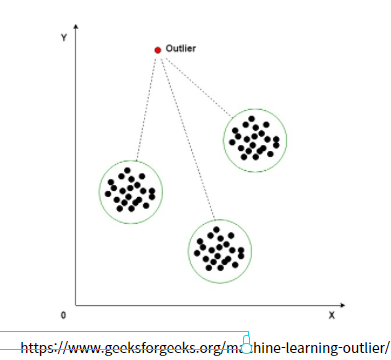
k개의 Clustering을 만들어내고 그 밖의 점들을 이상치라고 정의를 내릴 수 있습니다. 아래 그림을 보면서 연상하면 대략 이상치를 탐지할 수 있을 것 같다는 생각을 할 수 있습니다.
2) 마할라노비스 거리(Mahalanobis Distance)
고등학교 수학에서 일반적으로 배우는 거리는 원의 반지름과 같이 중심에서의 거리를 측정하는 개념입니다. 이러한 피타고라스 공식처럼 직각삼각형으로 거리를 구한 개념을 유클리안 거리라고 합니다.
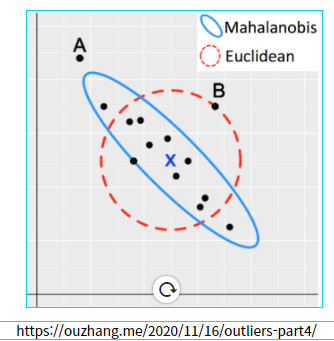
마할로노비스 거리의 개념은 대략적으로 위의 그림처럼 원이 아닌 타원으로 표시가 됩니다. 분포의 흩어진 정도 표준편차가 반영된 거리라고 보면 됩니다. 분포의 중심을 0으로 생각하고 2차원 축을 생각한 다음, 두 축의 각강에 표준편차1, 표준편차2 두 가지의 표준편차를 생각합니다. 각 점들이 중심(평균)으로 부터 몇 표준편차 만큼 떨어져있는지를 측정합니다. 표준편차 기반으로 거리를 측정하면 타원 모양으로 같은 거리가 나타나게 됩니다.
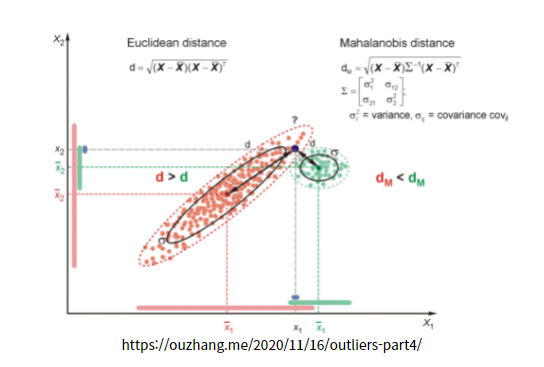
아래 그림 처럼 Principal Compent1, 2를 생각을 한다는 것은 대략 분포의 중심 축을 잡고 그 축으로 사영? 또는 프로젝션?을 내려서 1차원 분포를 본다고 생각을 합니다. 그 다음 그 분포의 표준편차1, 표준편차2를 구하고 각 축으로 정규화 Z=(X-M)/시그마 값으로 좌표축을 떠올리면 대략 한 바퀴의 타원의 점들은 같은 거리에 있다고 생각을 할 수 있고 이 개념이 마할라노비스의 거리가 됩니다.
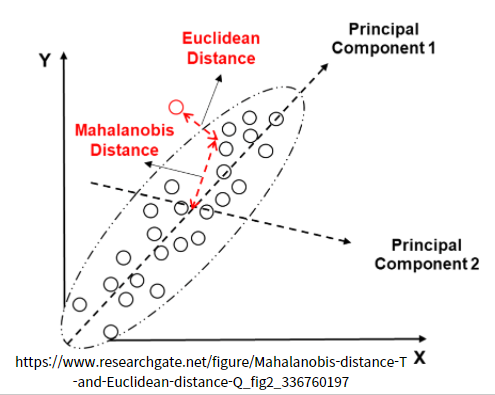
마할라노비스의 거리 개념으로 타원을 생각하고 3씨그마(표준편차) 이상 떨어진 점들을 이상치(Outlier)로 볼 수 있겠다는 생각을 직관적으로 이해해 볼 수 있습니다. 정확한 수식과 개념을 이해하려면, 공분산 행렬(Matrix)와 선형대수의 벡터 내적을 이해해야 수식을 이해할 수 있습니다. 오늘은 수식을 깊이 들어가지 않고 직관적인 의미로 마할라노비스의 거리 개념으로 탐지할 수 있겠다는 생각을 적어 보았습니다.

3) LOF(Local Outlier Factor)활용 이상치 탐지
LOF 방식은 밀도 측정 방식의 이상치(Outlier)탐지 방식입니다. 대략적인 방법은 A라는 점에서 적당한 반경(Neighborghood)를 잡고 반경의 내부의 점에서 근방의 밀도를 측정합니다. 이때 밀도라는 개념은 반경안에 대략 몇개의 점이 들어오는지를 측정합니다. 이러한 개념을 도입해서 수학, 통계공식을 만들어내면 LOF측정값을 만들어 낼 수 있습니다.
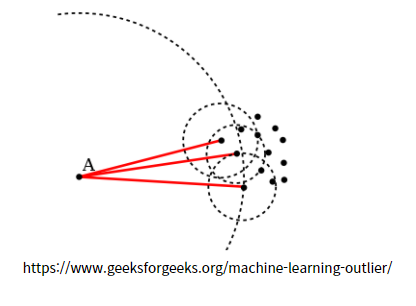
아래 Neighborhood 관련 수학 기호를 정의를 내리고 나면 아래와 같이 각 점에서의 LOF값을 정의 내릴 수 있습니다.

수식이 어떤 의미를 가지는 지는 수식 유도 과정과 어떻게 정의를 내리는지 살펴보아야합니다. 오늘 포스팅에서는 수식을 깊게 들어가기 보다는 결과에 집중하려고 합니다. 위의 공식처럼 수식을 정리하면 LOF의 값에 따라 Outlier를 찾아 낼 수 있습니다.
- LOF < 1 : 주변 밀도 있는 점들의 내부에 존재
- LOF = 1 : 주변의 밀도와 비슷
- LOF > 1 : 이상치(Outlier)
위에서 정의내린 수식을 특정 코딩 툴을 통해서 계산해내면 각점들의 LOF값들을 정리할 수 있습니다. LOF>1보다 큰 점들 중에서 특히 값이 큰 점들을 이상치(Outlier)로 생각해 볼 수 있습니다. LOF의 결과를 계산한 글을 찾아서 이미지를 첨부 해보았습니다.

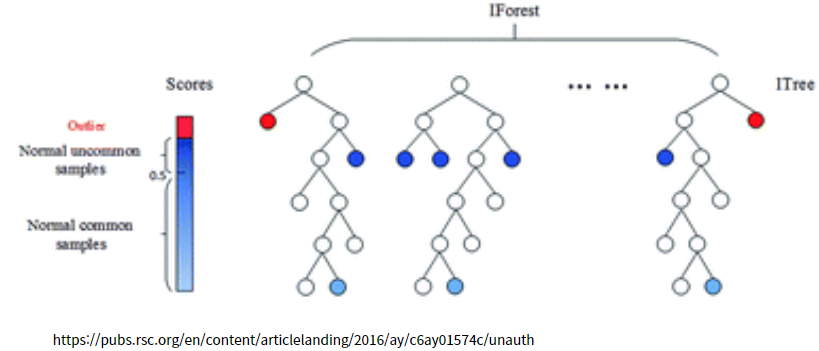
4) iForest(Isolation Forest) 기법 활용 이상치 탐지
의사결정나무(Tree)를 만들어 가면서 고립(Isolation)된 점을 찾아서 Outlier를 탐지하는 방법입니다. 아래 그림과 같이 Tree를 생각해보면,
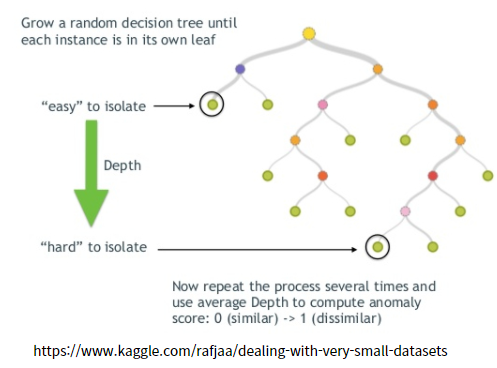
Data를 Tree 형태로 분리해나가면 처음 고립된 점들이 Outlier일 수 있겠다는 생각이 직관적으로 듭니다. 하지만 어떻게 저런 Tree(나무)형태로 가지치면서 내려갈 수 있을까??라는 생각을 가지게 됩니다.
이런 궁금증을 가지던 찰나, 위키피디아에서 iForest 그림을 보면서 직관적으로 어떻게 Isolate 된 점을 찾는지 이해할 수 있었습니다. 다음 그림을 한번 보겠습니다.
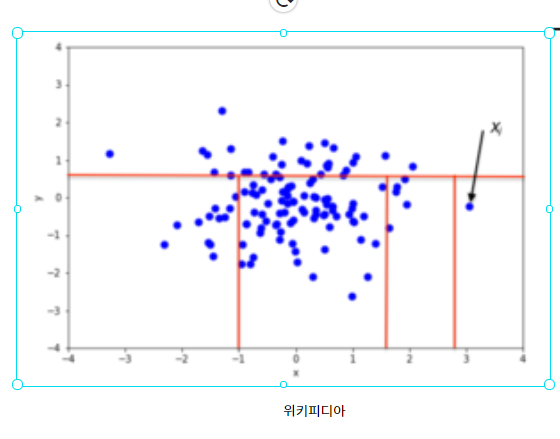
임의이 2차원 Data Set에서 사각형으로 5개의 파티션을 나누었다고 생각을 합니다. 그러면 오른쪽 아래의 파티션만 1개의 점이 나타나게 되고 오른쪽 아래의 파티션은 더 이상 파티션을 나눌 수 없게 됩니다. 다른 파티션은 여러개의 점들이 있으니 다시 파티션을 나눌 수 있습니다. 이렇게 파티션을 나우면서 나오는 점들을 Forest(나뭇가지)형태로 계속 가지치기를 할 수 있습니다. 위키피디아의 다음 그림을 보아도 여러번 파티션을 나누다보면 고립된(Isolated) 점을 찾아낼 수 있다는 생각을 가질 수 있습니다.
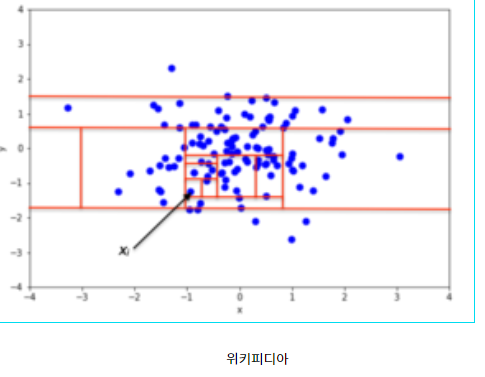
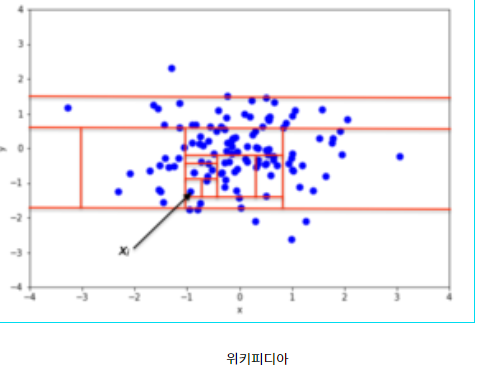
또한 여기서 파티션을 직사각형으로 나누었는데 Random한 모양으로 나누어서 Tree를 만든다고도 생각 할 수 있습니다.
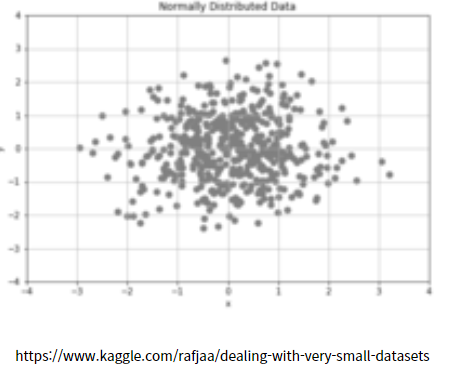
위의 캐글에서 참조한 그림에서 보듯이 파티션을 랜덤하게 나누어서 여러번 Tree를 만들어 나가면 이상치(Outlier)를 찾아 내는 하나의 방법이 된다고 이해할 수
있습니다.
6. 이상치 탐지 정리하며...
데이터 분석에서 이상치 처리는 중요한 부분이라고 생각이 들기에 많은 자료 조사, 고민, 생각 끝에 정리해서 오늘 포스팅을 정리하게 되었습니다. 막상 이상치 탐지 기법을 조사해보니 포스팅 내용보다 더욱 많은 기법들이 있었습니다.
1) 기초통계량 활용
2) 시각화 방법
3) 머신러닝, 모델링 기법 활용
특히 머신러닝, 모델링 기법은 더욱 복잡하고 정교한 방법들도 많이 있었고 개념을 더욱 디테일하게 수학, 통계적으로 이해하고 코딩공부까지 해야할 공부는 많다고 생각을 했습니다. 오늘은 일단 이상치 탐지 방법을 나열하고 대략적인 아이디어를 이해해서 각 기법과 개념이 그림으로 그려지도록 이해하는데 초점을 맞추었습니다. 추후에 좀더 수학, 통계적인 해석 그리고 코딩 실습 등 중요한 내용을 공부해서 다루고자합니다.
[빅공남 유트브 채널 바로가기]

[빅공남! 통계 같이해요 바로가기]

[빅공남! 문과생을 위한 고등수학 13강]

'빅데이터 > 통계노트' 카테고리의 다른 글
| 변수선택(필터/랩퍼/임베디드) [빅공남! 통계 같이 공부해요] (0) | 2021.12.31 |
|---|---|
| 변수 Feature vs Target, Feature Engineering [빅공남! 통계 같이 공부해요] (0) | 2021.12.30 |
| 결측값 결측치 종류 및 대체 (MCAR MAR MNAR) [빅공남! 통계 같이 공부해요] (0) | 2021.12.28 |
| 결측값 vs 이상값 Missing Value vs Outlier 이상치 vs 결측치 [빅공남! 통계같이 공부해요] (0) | 2021.12.28 |
| Preprocessing vs EDA 전처리 vs 탐색적 데이터 분석 [빅공남! 통계같이 공부해요] (0) | 2021.12.28 |




댓글