변수 Feature vs Target, Feature Engineering [빅공남! 통계 같이 공부해요]

빅데이터 분석기사 빅분기 변수 Feature Label Feature Engineering 는 빅데이터 탐색 2과목에서 하나의 주제와 관련이 있습니다. 데이터 검정사이트에서 2과목 빅데이터 탐색에서 데이터 전처리 두번째 주제가 분석 변수 처리입니다.

데이터 전처리 과목은 크게 데이터 정제와 분석 변수처리로 나눌 수 있습니다. 분석 변수처리의 소주제로는 다음과 같습니다.
1) 변수 선택 (Feature Selection)
2) 차원 축소 (Dimension Reduction)
3) 파생 변수 (Derived Variable)
4) 변수 변환 (Variable Transformation)
5) 불균형 데이터 처리 (Under/Over Sampling)
위의 주제를 공부하기 앞서, Feature와 Label의 차이에 대해서 정리를 하고 데이터 싸이언스의 한 과정인 Feature Engineering은 무엇을 하는 단계인지 알아보고자 합니다.

1. Feature Engineering 이란?
Feature Engineering은 데이터 정제 및 변환 과정 (Clean and Transform)을 통하고 Feature를 만든다고 합니다. Feature는 데이터 모델링에 쓰이는 변수라고 생각하면 되는데요.. 아래 그림을 먼저 발췌해서 보면 이해하는데 도움이 됩니다.
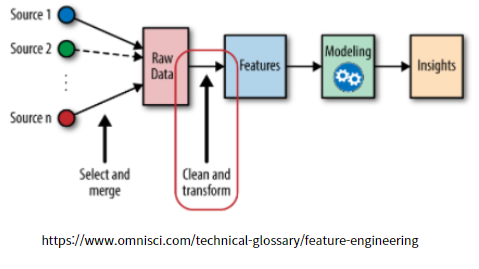
위의 그림을 보면 일단 Modeling에 앞서 Feature를 만든구나? 정도는 이해가 가는데 아직 확실히 무엇인지는 감이 잘 오지 않을 것입니다. 그래서 좀 더 직관적으로 과정을 이해할 수 있는 그림을 찾아보았습니다.
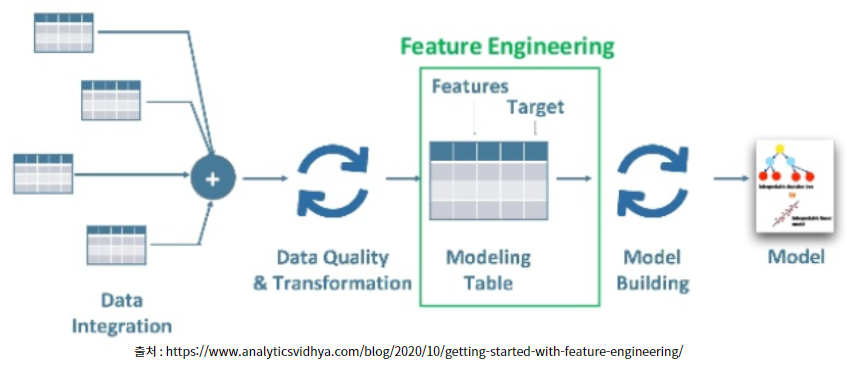
위의 그림을 보면 수집된 Data를 전처리 과정에서 데이터 정제와 변환 (Data Quality & Transformation) 이후에 Feature Engineering을 한다고 설명이 되어있습니다. 위의 그림에서 주의깊게 봐야할 부분은 바로 Features와 Target입니다. 그림을 다시 확대해서 살펴보겠습니다.
데이터 분석 모델링을 하기 앞서 Features와 Target을 만드는 과정이 들어갑니다. 그러면 이제 Feature Engineering 과정에서는 Feature와 Target을 만드다고 했는데, 과연 두 변수의 차이에 대해서 공부하면 좋겠다는 생각이 들었습니다.
2. 독립 vs 종속 변수 ???
Feature와 Label에 대해서 이해하려면 먼저 초등학교 수학으로 돌아가서 생각을 해보겠습니다. 수학 수업시간에 함수에 대해서 배우기 위해서 다음 그림을 한번씩은 접하게 됩니다.
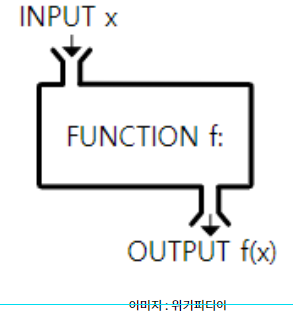
그림처럼 f(x) = x+1이라는 함수가 있다면,
x=1 대입 ☞ f(1) = 2
x=2 대입 ☞ f(2) = 3
x=-1 대입 ☞ f(-1) = 0
Input인 x의 값에 따라서 y=f(x)의 Output 결과가 나오게 됩니다. 이처럼 데이터 싸이언스에서 머신러닝, 알고리즘을 통해 데이터 분석을 한다는 것은 관측된 데이터로부터 규칙?을 찾아내고 예측?하는 것입니다. 그래서 예측?을 하기 앞어서 규칙?을 찾는 다는 것은 Input에 해당하는 변수를 찾는 것과 같습니다. 자, 이제 Input X와 결과 Y를 다음과 같이 생각해 볼 수 있습니다.
1) 독립변수(Independent Variable)
☞ 데이터의 원인에 해당하는 변수
☞ 독립변수의 의미는 원인(결과에 영향을 줌)이라는 의미로 독립이라는 단어 사용
2) 종속변수(dependent Variable)
☞ 데이터 결과에 해당하는 변수
☞ 종속변수의 의미는 결과(원인에 의해서)는 영향을 받는다는 의미로 종속이라는 단어 사용
3. Feature vs Label?? 동의어?? 차이??
데이터의 원인에 해당하는 변수인 독립변수와 데이터의 결과에 해당하는 종속 변수가 Feature와 Label에 해당합니다. 그래서 원인(Feature) vs 결과(Label)은 여러가지 용어로 사용되며 머신러닝, 통계 에서는 주로 Feature vs Label 또는 Feature vs Target으로 사용됩니다. 그리서 데이터 싸이언스를 공부하는 입장에서 Feature란 용어에 대해서 친해져야 한다는 생각이 들었습니다. 아래 그림으로 변수 용어에 대해서 쉽게 이애할 수 있도록정리해보았습니다.

1) 독립변수(Independent Variable)
☞ 데이터의 원인에 해당하는 변수
☞ 독립변수의 의미는 원인(결과에 영향을 줌)이라는 의미로 독립이라는 단어 사용
☞ Feature (머신러닝,통계에서 주로 사용하는 어휘)
☞ Attribute (속성? 원인을 알면 속성을 안다는 의미)
☞ Predict(원인으로 결과 예측)
☞ Explanatory(설명? 원인을 설명)
☞ Control (원인으로 예측 ☞ 통제 가능)
☞ Manuplate (원인으로 예측 ☞ 예측결과 통제)
2) 종속변수(Independent Variable)
☞ 데이터 결과에 해당하는 변수
☞ 종속변수의 의미는 결과(원인에 의해서)는 영향을 받는다는 의미로 종속이라는 단어 사용
☞ Label (알고자 하는 결과)
☞ Target (표적으로 삼고자 하는 결과)
☞ Response(원인에 의한 응답)
☞ Outcome(결과)
☞ Class
4. Feature 와 차원(Dimension)??
변수를 2가지 (원인 vs 결과) 관점에서 Feature와 Label을 정리했습니다. 데이터 분석에서는 어떤 결과(Label)을 예측하기 위해서 먼저 어떤 원인 변수(Feature)를 찾을 것인가가 중요합니다. 그래서 아래 그림을 보면 좀더 이해에 도움이 됩니다.
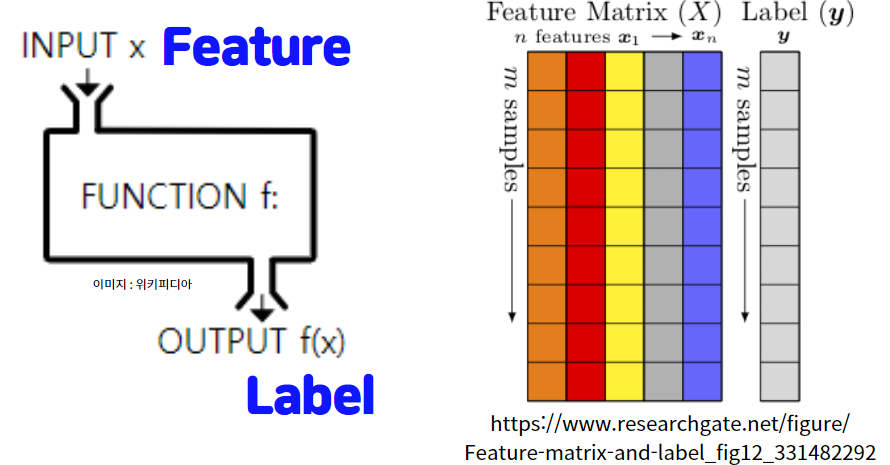
Feature Matrix를 잡는 다는 것은 원인 변수를 몇개 선택할 것인가?에 대해서 생각이 들 수 있습니다. 예를 들어서, 부동산 시장으로 설명을 해보면 부동산 가격을 알고자하는 결과(y) 즉, Label이라고 생각하겠습니다. 그러면 관측된 Data로 y에 영향을 주는 원인(Feature)을 찾아봅니다. Feature인 x는 금리, 시장공급, 시장수요, 정책 등등 여러가지 원인이 있을 수 있습니다. 어떤 학자는 원인을 5개로 분석할 수 있고 어떤 학자는 원인을 더 찾아서 10개로 분석할 수 있습니다. 그래서 Feature를 고른다음에 주로 영향을 주는 변수가 몇개인지 찾습니다. 그래서 영향을 주는 변수의 개수가 차원(Dimension)이 됩니다. 무조건 차원을 늘린다고 좋은 결과가 나오는 것도 아니고, 차원을 줄인다고 좋은 결과가 나오는 것이 아닐 것입니다. 그래서 Overfit, Underfit (과소/과대 적합)의 이슈도 발생합니다.
5. Feature Engineering과 관련된 이슈
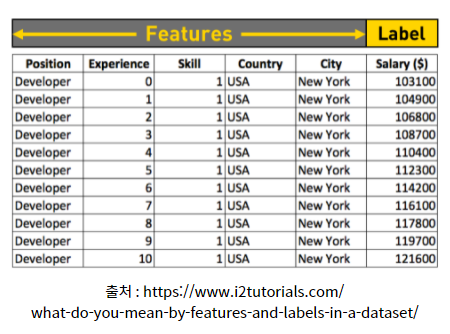
Feature와 Label의 개념을 위에서 살펴보았고 이제 Feature Enineering의 과정에 대해서 다시 한버 생각해보겠습니다. 관측된 Data로 부터 원인과 결과 즉, Feature vs Label을 선택합니다. 여기서 중요한 이슈가 생깁니다.
1) Feature (원인 변수)를 어떻게 찾을까?
☞ 변수 선택 (Feature Selection)
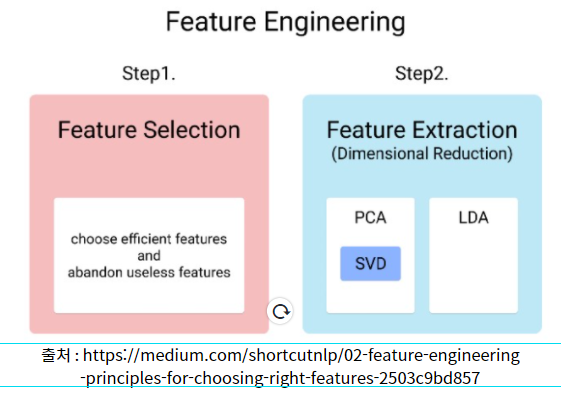
2) Feature Extraction
☞ 변수 추출 ☞ 차원 축소
☞ 차원 축소? (Dimension Reduction)
☞ PCA(주성분 분석), LDA, SVD

1) 머신러닝 알고리즘의 정확도 향상
2) 과적합(Overfitting Problem) 해결
3) 계산 속도 향상
4) 머신러닝 알고리즘의 불안정성 해결
5. Feature vs Label 포스팅 정리하며...
데이터 분석에서 변수 선택 및 처리는 중요한 과정 중에 하나입니다. 머신러닝, 알고리즘 등 데이터 분석을 하기 앞서 변수 선택이 잘못 된다면, 정확성 및 효율성 뿐만아니라 불필요한 계산량도 증가되어 비용(속도)증가 등으로 원하는 결과를 예측할 수 없게 됩니다. 때문에 데이터 정제 과정 이후에 분석에 앞서, Feature(원인 변수)를 적절하게 찾아내는 과정이 필요하고 이는 Feature의 차원(Dimension)과 영향이 있습니다. 사실, 차원의 개념은 수학과 관련이 있습니다. 선형대수(Linear Algebra)의 벡터, 행렬, 기저(Basis), 차원(Dimension), 직교기저 등 수학적 개념이 뒷받침 되어야 데이터 분석을 할 수 있다고 생각합니다.
수학을 전공한 빅데이터를 공부하는 남자 빅공남은 추후 선형대수와 관련해서 쉽게 이해할 수 있는 내용을 정리해보고자 합니다. 오늘 긴 포스팅은 여기서 마치겠습니다.
★구독과 좋아요★
빅공남을 춤추게 합니다 !!
[빅공남 유트브 채널 바로가기]

[빅공남! 통계 같이해요 바로가기]

[빅공남! 문과생을 위한 고등수학 13강]

'빅데이터 > 통계노트' 카테고리의 다른 글
| 공분산 Covariance 란 무엇인가??? [빅공남! 통계 같이 공부해요] (3) | 2021.12.31 |
|---|---|
| 변수선택(필터/랩퍼/임베디드) [빅공남! 통계 같이 공부해요] (0) | 2021.12.31 |
| 이상값 이상치 Outlier 탐지 [빅공남! 통계 같이 공부해요] (0) | 2021.12.28 |
| 결측값 결측치 종류 및 대체 (MCAR MAR MNAR) [빅공남! 통계 같이 공부해요] (0) | 2021.12.28 |
| 결측값 vs 이상값 Missing Value vs Outlier 이상치 vs 결측치 [빅공남! 통계같이 공부해요] (0) | 2021.12.28 |




댓글