Feature Selection Feature Extraction 차원축소 PCA LDA t-SNE SVD [빅공남! 통계 같이해요]

Feature Selection Feature Extraction 변수 선택 변수 추출 무슨 차이가 있을까? 차원 방법은 크게 변수 선택과 변수 추출로 나누어서 생각해볼 수 있습니다. 오늘 포스팅에서는 두 차이점이 무엇인지 알아보고 각각의 기법이 어떤 것들이 있는지 흐름만 잡는 포스팅과 유튜브 영상을 준비했습니다. 관련 링크는 포스팅 하단에 첨부하도록 하겠습니다.
1. 변수 선택 vs 변수 추출 (Feature Selection vs Extraction)
1) 변수 선택 : n개의 변수중에서 부분적으로 몇개를 사용할지 선택함.
2) 변수 추출 : n개의 변수 중에서 원본 데이터를 설명하면서 적은 개수로 new Feature 생성하고 new Feature의 Linear/Nonliear한 결합으로 만든 공간으로 원본 데이터를 투영 시켜서 표현함.
무슨 차이점이 있을까?
아래 그림 처럼 Featur Selection은 원본 데이터의 변수 중 몇개를 선택해서 차원을 축소하는 방법입니다. 변수의 변화를 주는 것이 아니라 몇개를 골라서 전체를 표현할 것인가의 문제입니다.
그런데 아래 그림처럼 Feature Extraction은 3개의 Feature로 적절한 조합을 통해서 new Feature1과 new Featrue2를 생성해서 분포를 나타냅니다. Feature Selection과 달리, 2차원으로 축소는 되었으나, Feature1,2,3의 정보를 어느 정도 가지고 있는 new Feature로 변환된 것을 시각화 한 그림입니다.
그래서 Feature Extraction이라는 것은 원본을 설명하는 새로운 변수로 변환해서 차원을 줄이고 원본을 설명하는 변수를 찾는 과정이라고 볼 수 있습니다.
아래 그림을 통해서도, Feature Extraction과 Selection의 차이점을 쉽게 눈으로 이해할 수 있습니다.
2. 변수 선택 (Feature Selection)
변수 선택기법은 크게 3가지 방법으로 볼 수 있습니다.
1) Filter Method
2) Wrapper Method
3) Embedded Method
자세한 내용은 빅공남 통계 11번째 포스팅에 정리했습니다. 링크 첨부합니다.
변수선택(필터/랩퍼/임베디드) [빅공남! 통계 같이 공부해요]
필터 랩퍼 임베디드 3가지 기법 분석 변수 처리에 관해서 오늘 포스팅을 준비했습니다. 2과목 빅데이터 탐색에서 데이터 전처리 두번째 주제가 분석 변수 처리입니다. 위의 주제를 공부하기 앞
seeyapangpang.tistory.com
3. 변수 추출 (Feature Extraction)
차원을 축소하면서 원본 데이터셋을 표현하는 Feature Extraction은 아래와 같은 방법 등이 있습니다.
특히나 대표적인 방법인 주성분분석 PCA 기법입니다.
1) PCA (Principle Component Analysis)
2) LDA (Linear Discriminant Analysis)
3) SVD (Single Value Decomposition)
4) NMF (Non-negative Matrix Factor)
5) t-SNE (t-Distributed Stocahstic NEighbor Embedding)
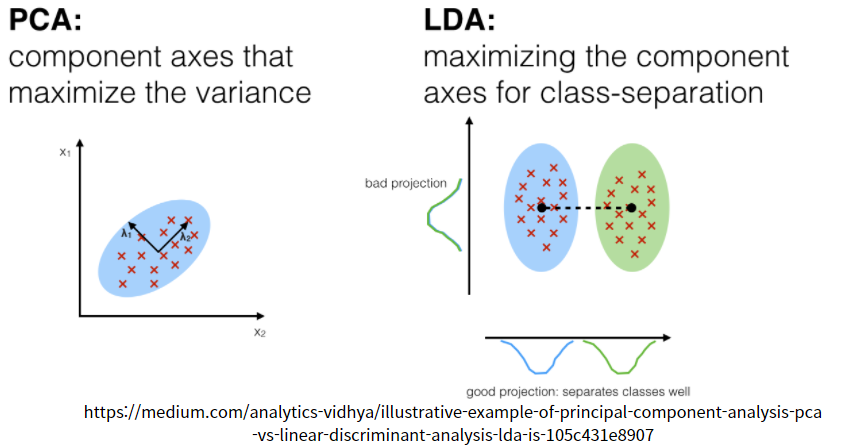
4. PCA vs LDA
PCA 기법과 LDA 기법 모두 Projection을 통해 차원을 축소하는 점에서는 비슷한 방법입니다. 하지만 차원을 축소하는 기법 방식은 다른 방식으로 접근합니다.
PCA : 분산을 최대로 하는 직선의 방향으로 축을 잡아감.
비지도 학습(Unupervised)
LDA : Class간 분류를 위해 Class간 분산이 커지는 방향을 잡아감.
Class내부 데이터 끼리의 분산은 작아지는 방향으로 잡음.
지도 학습 (Supervised)
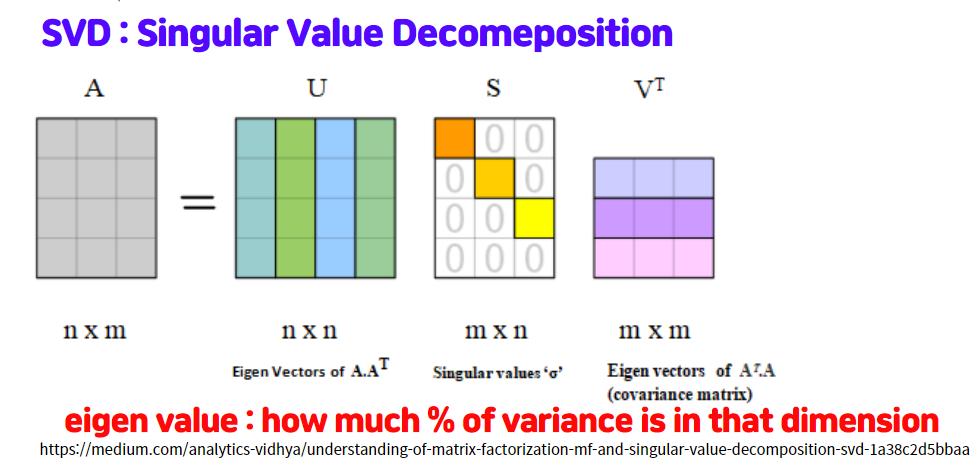
4. SVD
SVD 기법은 nxm matrix를 USV^T형태로 행렬 인수분해를 하고 나서 분산이 큰 방향을 잡아가면서 차원을 축소하느 방법을 말합니다. 아래 그림처럼 행렬을 분해하고 적은 개수의 차원으로 분리하는 것을 이해할 수 있습니다.
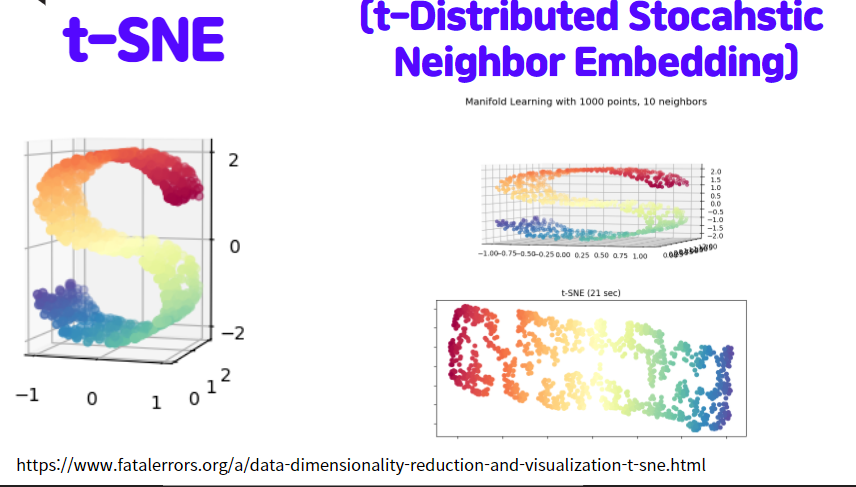
5 t-SNE
t-분포에 확률 기법을 이용해서 다양체(Mainifold)의 데이터를 2차원 또는 3차원으로 차원축소 시키는 것을 의미합니다. 아래 그림가 같이 S자 형태의 데이터가 있는데서, 정사영(Projection) 시키는 것이 아니라 S자 곡면을 쭉 늘린것 같은 2차원 평면으로 만들명 데이터를 만들어내고 사영시키는것을 의미합니다.
| Scree Plot PCA Eigenvalue Explained Ratio [빅공남! 통계 같이해요 ] (0) | 2022.02.09 |
|---|---|
| PCA Principle Component Analysis 주성분분석 [빅공남! 통계 같이해요] (0) | 2022.02.05 |
| Vector Inner Product Dot Product 벡터 내적 선형대수 [빅공남! 통계 같이해요] (0) | 2022.01.27 |
| 정사영 Projection 2d to 1d 2차원 1차원 차원축소 [빅공남! 통계 같이해요] (0) | 2022.01.25 |
| Dimension Reduction 차원 축소 이유 Why? [빅공남! 통계 같이해요] (0) | 2022.01.24 |




댓글