MinMax Standard Robust Scaler 변수 변환 [빅공남! 통계 같이해요]

MinMax Scaler Standard Scaler Robust Scaler 빅데이터 분석기사 빅분기 통계 2과목 소주제 변수변환에 대해서 공부를 정리하고자 합니다. 특히, 오늘 포스팅에서는 Scaler 종류 3가지에 대해서 포스팅과 유튜브 영상으로 정지를 하려고합니다. 먼저 변수변환에 대해서 알아보고, 각 Scaler의 이론적인 의미 그리고 파이썬 코딩실습 등으로 내용을 살펴보겠습니다. 유튜브 공부영상 링크는 포스팅 맨 하단에 첨부하겠습니다.
빅데이터 분석기사 목차를 다시 한번 살펴보고자 합니다. 목차를 보면 변수변환이라는 소주제를 확인할 수 있습니다.

데이터 검정에서 공개된 빅분기 작업형 예제 1번을 보면 다음과 같습니다.

오늘 포스팅은 Min-Max Scaler와 같은 변수변환이 어떤 의미인지에 관해서 이론적인 내용과 코딩으로 같이 공부를 하고자합니다.
1. 변수 변환이란?
변수 변환이란 수집된 데이터를 데이터 분석에 필요한 형태로 바꾸는 것을 의미합니다. 데이터의 스캐일(Scale)을 변환 시키거나 범주형, 연속형의 데이터를 서로 변환하거나, 함수를 통해서 데이터의 분포를 바꾸는 등등 의작업을 의미하고 데이터 전처리(Preprocessing)에 과정이 포함되게 됩니다.
변수변환을 크게 4가지로 분류할 예정이며, 오늘 포스팅에서는 주로 Scaling을 다루도록 합니다.
- Scaler(Min-max, Z-score, Robust)
- 구간화(Binning)
- 더비 변수(Dummy Variable
- 함수 변환(지수,로그,루트,역수 등등....)
2. 스캐일러(Scaler)?
- 데이터의 스캐일(범위)를 바꿈.
- 상대적인 수치의 데이터로 변환
- 데이터 특성에 다라 크기 또는 범위가 다르기 때문에
- 상대적인 개념의 변수로 변환
- MinMax. Z-score, Robust Scaler 3가지 정리하려고함.
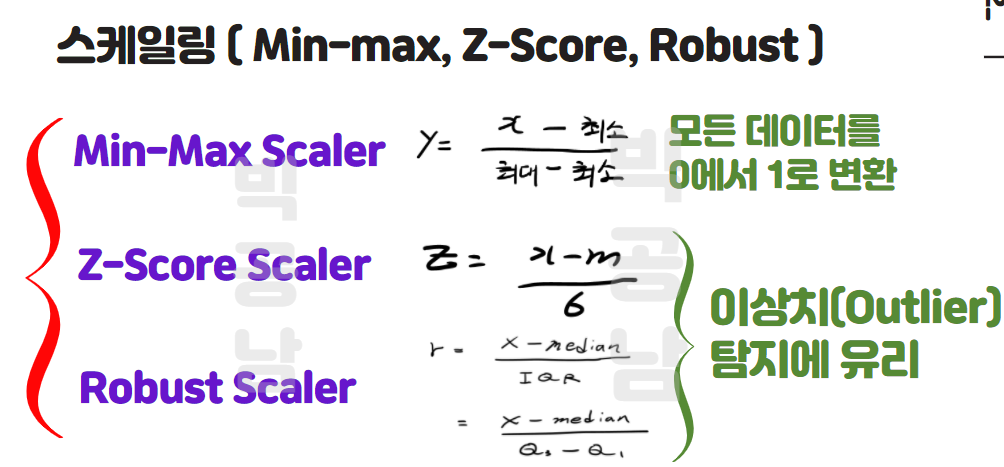
3. Min-Max Scaler
Min-Max Scaler는 데이터의 최대값, 최소값으로 차로 나누어서 0과 1사이의 값으로 변환하는 것을 의미합니다. 아래 그림과 같이, 수집된 Data를 Min-Max Scaler 변환 식으로 변수변환을 하게 되면 변수 y로 변하게 됩니다. 아래 그림과 같이 0에서 1사이의 값으로 변환 되는 것을 알 수 있습니다.

예를들어, 변환된 데이터가 0.5를 나타내면, (min+max)/2를 나타낸 다는 것을 빠르게 직관적으로 알 수 있습니다. 이처럼 Min-Max Scaler로 변환하게 되면 최대,최소값에 대한 상대적인 위치를 간단하게 나타낼 수 있게 됩니다.
하지만 Min Max Scaler는 최대, 최소값으로 Scale을 변환하기 때문에, 이상치(Outlier)에 취약할 수 있습니다. Normal한 분포에서 하나의 값이 이상하게 크게 나온다고 생각을 해봅니다. 하나의 이상한 값 때문에 이상치 최대값이 1을 나타내게 되며, 전체적인 분포를 잘 설명할 수 없게 됩니다. ex) 전체적으로 0`~10인 분포에서 이상치 1000인 값이 나온다면?
Scaler 변환으로 변수간에 상대적 거리는 사이즈를 축소하지만 비율은 유지하면서 줄이는 것을 의미합니다. 그렇지만, 이상치(Outlier)에 취약하기 때문에 다른 Scaler를 사용하기로 합니다. 바로 Standard Scaler, Robust Scaler 등입니다.
4. Standard Scaler
분포가 대략적으로 정규분포에 가까운 분포라고 가정을 합니다. 그러면 정규분포(Normal Distribution)의 표준화 과정을 통해서 표준 정규분포로 나타낼 수 있습니다. 이처럼 표준정규분포로 만드는 과정처럼 평균과의 거리를 표준편차로 나눠주는 방법을 통해서 변수 변환을 할 수 있습니다. 아래 그림을 보면서 변환에 대해 이해하도록 하겠습니다.

평균에 해당하는 변수는 0으로 변환이 되게 됩니다. 나머지 변수는 평균으로 부터 그리가 표준편차 몇칸인지로 바뀌게 됩니다. 예를 들어, 평균에서 오른쪽으로 1표준편차 만큼 떨어진 데이터는 +1로 변환이 되게 됩니다. 변환된 데이터에서 +2는 평균에서 오른쪽으로 2표준편차 만큼 떨어진 것으로 볼 수 있습니다. 이처럼 평균으로부터 몇시그마(표준편차) 떨어져있는지로 바꾸는 과정이 Standard Scaler (Z-Score)라고 합니다. Min-Max Scaler에서 이상치에 취약하다고 설명했었는데, 이상치를 탐지할 수 있고 이상치 처리를 할 수 있는 변수 변환 방법입니다.

5. Robust Scaler
이번에는 Robust Scaler에 대해서 알아보고자 합니다. Robust Scaler는 평균이 아닌 Median(50%지점)에서 몇 IQR만큼 떨어져 있는지로 변수 변환을 하게 됩니다. 아래 그림으로 이해해보도록 하겠습니다.

Box Plot 에서 Q1(25%), Q2(50%),Q3(75%) 지점으로 나누었고, IQR(사분위 편차)개념이 등장합니다. 이상치 탐지에서 공부했던 Box Plot을 다시 리뷰해봅니다.

IQR은 Q3(75%) - Q3(25%) 지점간 거리를 의미하며, Meidan으로 부터 몇 IQR로 떨어져 있는지로 변수변환 하는 방법이 바로 Robust Scaler입니다. 여기서 특이한 점은 평균(Mean)이 아닌 중위값(Median)이기 때문에 변수 변환에도 이상치(Outlier)의 영향을 크게 받지 않게 됩니다. 이처럼 Robust Scaler도 이상치 탐지를 빠르게 알아볼 수 있는 변수 변환 방법중에 하나입니다.
6. 구글 코랩 활용 파이썬 코딩 (MinMax/Standard/Robust)
MinMax Scaler, Standard Scaler, Robust Scaler를 모두 싸이킷런을 이용해서 변수변환을 진행해볼 수 있습니다. 다음 코딩과 같이 실습을 해볼 수 있습니다. 핵심 코딩은 다음과 같습니다.
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import RobustScaler
Scaler_mmx = MinMaxScaler()
Scaler_std = StandardScaler()
Scaler_rbst = RobustScaler()싸이킷런.전처리에서 MinMax Scaler, StandardScaler, RobustScaler를 불러와서 사용할 수 있습니다. Scaler의 이름을
Scaler_mmx
Scaler_std
Scaler_rbst
로 임의로 이름을 지어서 사용했습니다. 구
글 코랩 G드라이브에 mtcars.csv 데이터 파일을 저장했습니다. 구글 코랩에서 G드라이브를 연동 시키는 방법은 다음 명령어로 할 수 있습니다.
from google.colab import drive
drive.mount('/content/drive')다음과 같이 판다스에서 csv를 가지고 올 수 있습니다.
import pandas as pd
import numpy as np
df = pd.read_csv('/content/mtcars.csv')
df데이터의 결과는 다음과 같이 구글 코랩에서 볼 수 있습니다.

데이터를 3가지 Scaler로 변환하기 위해서 구글 코랩에서 다음과 같이 실행을 해보았습니다.
import pandas as pd
import numpy as np
df = pd.read_csv('/content/mtcars.csv')
subdf = df['qsec']
x=subdf.values.reshape(-1,1).round(1)
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import RobustScaler
Scaler_mmx = MinMaxScaler()
Scaler_std = StandardScaler()
Scaler_rbst = RobustScaler()
y = Scaler_mmx.fit_transform(x).round(1)
z = Scaler_std.fit_transform(x).round(1)
r = Scaler_rbst.fit_transform(x).round(1)
result = pd.DataFrame({'Origin':x.tolist() , 'MinMax':y.tolist(),'Standar':z.tolist(),'Robust':r.tolist()})
resultSclaer 실행화면.

7. 구름 IDE 작업형 예제 1번 실습환경에서 코딩
다음은 빅데이터 분석기사 작업형 1번 실기 예제 실습환경에서 코딩을 해볼 수 있습니다.
구름EDU - 모두를 위한 맞춤형 IT교육
구름EDU는 모두를 위한 맞춤형 IT교육 플랫폼입니다. 개인/학교/기업 및 기관 별 최적화된 IT교육 솔루션을 경험해보세요. 기초부터 실무 프로그래밍 교육, 전국 초중고/대학교 온라인 강의, 기업/
edu.goorm.io
아래와 같은 방법으로 코딩을 작성했고 3가지 스케일러를 확인해 볼 수 있었습니다.
[코딩 실습 화면]

[코딩 결과]

8. 정리하며...
오늘 포스팅에서는 변수변환 기법 중에 하나로 Scaler에 대해서 공부를 해보았습니다. 3가지 Scaler로 MinMax, Standard, Robust Scaler를 공부했습니다. Data를 Scaler 변환을 통해서 특정 분포의 데이터로 바꾸는 과정을 이해할 수 있었고, 파이썬 코딩싨브을 통해서 변환하는 연습도 해보았습니다. 이론적인 내용과 코딩실습 등 데이터 분석을 같이 공부할 수 있는 유익한 포스팅 및 유튜브 영상 앞으로 열심히 만들도록 하겠습니다.
'빅데이터 > 통계노트' 카테고리의 다른 글
| Log Transformation 로그/지수/제곱/루트/역수 함수변환 [빅공남! 통계 같이해요] (3) | 2022.03.26 |
|---|---|
| 구간화(Binning) 더미변수(Dummy Variable) pd.cut[빅공남! 통계 같이해요] (0) | 2022.03.09 |
| 파생변수 요약변수 Derived Variable Summary Variable [빅공남! 통계 같이해요] (0) | 2022.03.01 |
| SVD Singular Value Decomposition 특이값분해 [빅공남! 통계 같이해요] (1) | 2022.02.24 |
| LDA Linear Discriminant Analysis [빅공남! 통계 같이해요] (0) | 2022.02.14 |




댓글