파생변수 요약변수 Derived Variable Summary Variable [빅공남! 통계 같이해요]

파생변수 요약변수 빅데이터 분석기사 2과목 주제 중에 하나인 파생변수에 대해서 정리해보고자 합니다. 지난 포스팅까지는 차원축소에 대해서 여러 포스팅으로 나누어서 정리를 했었습니다. 오늘은 주로 파생변수와 요약변수의 차이점과 특징에 대해서 알아보고자 합니다. 데이터 검정 사이트에 가면 빅데이터 분석기사 필기 시험에 대한 설명을 볼 수 있습니다. 아래 그림은 데이터 검정 사이트에서 2과목 빅데이터 탐색의 소주제를 참조해서 가지고 왔습니다.

1. 데이터 마트(Data Mart)?
파생변수에 대해 공부하기 앞서 데이터 마트에 대해서 살펴보고자 합니다. 데이터 웨어하우스, 데이터 마트라는 저장공간이 있습니다. 데이터 웨어하우수(DW), 데이터 마트(DM)을 알아보고자 아래 그림을 보면서 이해해보고자 합니다.

수집된 데이터(Raw Data)는 ETL 프로세스를 거쳐서 데이터 창고인 Data Warehouse에 정리가 되어 저장이 됩니다. 이러한 데이터는 각 주제별 또는 각 부팀별로 분석하고자 하는 형태로 정리가 되어서 데이터 마트 Data Mart에 저장이 됩니다. 데이터 마트(DM)에 저장된 데이터는 분석을 위한 데이터들로 분석에 필요한 변수들을 생성하게 됩니다. 여기서 등장하는 개념이 파생변수(Derived Variable)와 요약변수(Summary Variable)입니다.
2. 파생변수 vs 요약변수?
데이터 마트(DM)에서 생성된 변수 파생변수와 요약변수는 아래와 같이 정리해 볼 수 있습니다.
1) 요약변수(Summary Variable) : 수집된 데이터의 요약 또는 종합(Aggregate), 집계, 빈도, 횟수 등등...
ex) 최근1개월 상품 구매건수, 최근1개월 상품 구매가격, 최근1개월 상품 총 구매금액 등등...
2) 파생변수(Derived Variable) : 주관적인 의미의 변수
ex) 고객구매등급, BMI지수, 수능표준점수 등등...
파생변수와 요약변수 중에 큰 차이는 파생변수는 주관적인 의미가 들어갈 수 있다는 점입니다. 아래 그림 예제를 통해서 어떤 의미인지 알아보도록 하겠습니다.
3. 요약변수(Summary Variable) 그림으로 이해하기
아래 그림과 같이 어떤 고객 구매 성향 및 구매 현황을 분석하기 위해서 아래 그림과 같이 데이터를 정리한다고 생각을 합니다. 즉. 고객 분석을 위해서 마트에 고객별로 다음과 같이 요약된 정보를 얻는 상황을 보겠습니다.

고객번호 222, 3333에 대해서 기간별 구매건수, 총금액, 평균 등을 요약(Summary)하는 새로운 변수를 만들 때 요약변수를 만들었다고 합니다.
이처럼 요약 변수에서는 총계(Aggragate)를 내기 위한 변수를 만들어 내는 것을 의미합니다. Summary하는 변수이기 때문에 정해진 값(?) ex)횟수? 총계? 을 변수화 하기 때문에 객관적인 정보가 될 수 있습니다. 분석에 도움이 될 수 있도록 Summary하는 변수는 데이터 마트에 자동생성을 하도록 자동화 할 수 있습니다.
4. 파생변수(Derived Variable) 그림으로 이해하기
파생변수는 아래 그림과 같이 예제를 통해서 파생변수를 이해해 볼 수 있습니다. 수집된 데이터는 이름, 몸무게(kg), 키(m)입니다. 이 데이터를 활용해서 비만의 정도를 분석한다고 생각합니다. 여기서 체질량지수라는 개념이 등장합니다. 비만의 정도를 나타내기 위해서 몸무게(kg)/키(m)^2 값을 bmi라고 합니다. 즉, bmi라는 새로운 변수를 몸무게와 키를 활용해서 어떤 변수로 만들어냈습니다. 만약 비만의 정도를 측정하기 위해서 3* 몸무게(kg)/키(m)^2 라고 변수를 새롭게 만들어도 어떤 측도가 될 수 있을 것입니다.
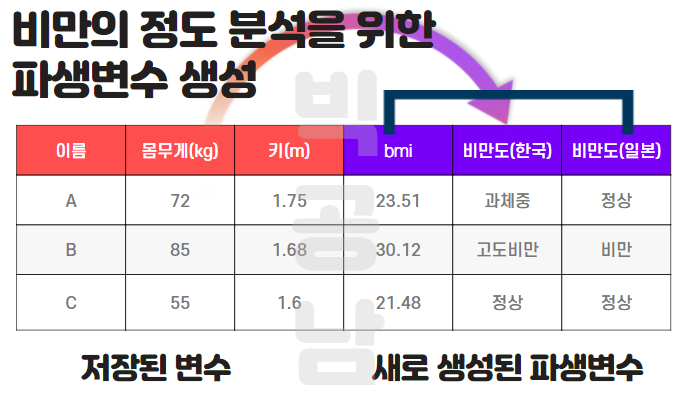
bmi라는 지표를 만들고, 이 bmi의 수치를 통해서 정상, 과체중, 비만, 고도비만 등을 나타내게 됩니다. bmi수치를 얼마나 주냐에 따라서 정상인지 비만인지 구분이 다르게 될 수 있는 부분입니다. 어떻게 구간을 주고 비만을 측정하느냐에 따라 정상이 될 수 도 있고, 비만이 될 수 도 있습니다.
이처럼 파생변수는 주관적인 변수가 될 수 있습니다. 집단을 분류하는 기준에 조건이 들어가기 때문에 조건을 어떻게 주느냐에 따라서 결과가 바뀌게 된느 것입니다. 때문에 파생변수를 생성할 때는 분석하는 결과와 비교하며 논리적으로 타당한지?에 대해서 검증을 해야합니다.
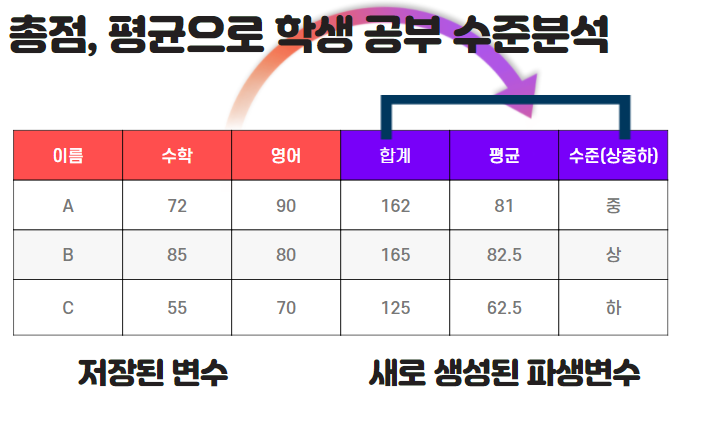
위의 그림처럼 총점, 평균 등으로 새로운 변수로 만들고, 평균으로 학생의 성취도(학업수준)을 평가하는 경우에도 학생 수준을 측정하는데 있어서 주관적인 조건이 들어갈 수 있습니다. 학업의 성취도를 상중하로 나누는 기준이 먼저 논리적으로 타당한지?에 대해서도 검증이 필요합니다.
파생변수(Derived Varaible)를 생성할 떄에는 주관성 때문에 논리적으로 타당한지 검증 그리고 어떤 수치가 대표성(특징을 나타내는지, 대표할수 있는지)을 가지고 있는지도 같이 살펴보아야 합니다.
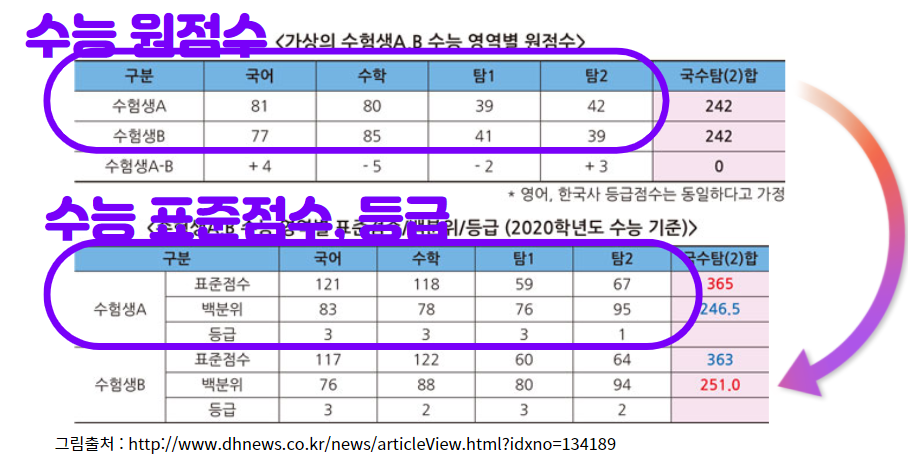
위의 그림처럼 수능 원점수를 표준점수, 수능등급으로 나타내서 새로운 변수를 만드는 경우에도 파생변수(Derived Variable)을 만들었다고 생각할 수 있습니다.
5. 파생변수(Derived Variable) 정리하기
1) 각 주제 부팀에서 데이터를 분석하기 위해서 새로운 변수를 조합해서 사용함.
2) 이때 어떻게 변수를 만들어 내는지에 따라서 주관적인 개념이 들어갈 수 있음.
3) 파생변수 생성시 논리적으로 타당한지 체크를 해야함.
4) 기존 변수의 연산, 조합, 분해, 함수, 조건문 등등으로 데이터를 새로 생성해서 변수를 만듦.
5) 파생변수의 예
- BMI 지수 = 몸무게/키^2 : 키와 몸무게로 새로운 BMI 지수 생성
- 수능 표준점수 : 원점수(0~100)로 표준편차가 반영된 점수 생성
- 수능 등급 : 원점수로 수능 몇 등급인지 생성
- 주민번호 : 주민번호로 성별 생성(남/여). 주민번호로 나이 생성
'빅데이터 > 통계노트' 카테고리의 다른 글
| 구간화(Binning) 더미변수(Dummy Variable) pd.cut[빅공남! 통계 같이해요] (0) | 2022.03.09 |
|---|---|
| MinMax Standard Robust Scaler 변수 변환 [빅공남! 통계 같이해요] (0) | 2022.03.08 |
| SVD Singular Value Decomposition 특이값분해 [빅공남! 통계 같이해요] (1) | 2022.02.24 |
| LDA Linear Discriminant Analysis [빅공남! 통계 같이해요] (0) | 2022.02.14 |
| Scree Plot PCA Eigenvalue Explained Ratio [빅공남! 통계 같이해요 ] (0) | 2022.02.09 |




댓글